2026-04-05
How to Design a Memory System for Agents
A practical approach to building memory systems that work with any model, even locally running small models.
Anthropic banned OpenClaw usage with their subscriptions and some were furious about it. We were wondering why those people couldn't use a different model. With OKBrain Harness, you can literally use any model & it won't make much of a difference.
Then we dug into how OpenClaw handles memory & data. We figured out why Claude's Opus works so well but others don't. We tend to agree with Anthropic in this case. Tokens are quite valuable & a scarce resource. We need to use them for good use.
How OpenClaw Memory works
We're not experts in OpenClaw, but here's how it usually works:
- Everything is stored in markdown files
- There is a
MEMORY.mdwhere agents write what they learn about the user - There are also daily summary .md files
- Agents can search for stored data & memory as needed
When it's running it loads some of these memories into the context and completes tasks. If the data can fit in the memory & the model can handle that, it will do wonders. Anthropic's Opus is really good at this sort of task.
But it's costly. In the case of Claude subscriptions, it's costly for Anthropic. Unlike Claude Code, their ROI for OpenClaw usage is minor. That's why they nuked the support for OpenClaw.
In this post, we'll show you how we designed the memory system for OKBrain Harness. It works with any model, even a locally running small Qwen model. It's token efficient and it knows everything about you.
OKBrain Harness is technically very different from OpenClaw. Our goal is to keep data & memory locally & give a similar experience to ChatGPT. But now, it's moving closer to what OpenClaw offers with scheduled jobs & etc.
But our memory solution is generic & can be used with any product. Let's talk about it.
Use of SQLite over Markdown
Memory is for LLMs. And they are good at tool calls & CLIs. So, we prefer a structured data format and provide various tools for LLMs to access the data.
The argument for using Markdown in OpenClaw is that humans can read these files. But we wonder how many humans really do that. With SQLite, you can simply query it or ask a coding agent to do it. It'd be a much better experience for humans as well.
Fact Extraction
OKBrain Harness has a background worker, which looks for all the chat conversations & extracts facts using an LLM. These facts are categorized into:
- core
- project
- technical
- transient
Basically, we feed the conversations and define what a fact is. Then simply ask an LLM to extract those facts. We initially used Gemini 3.0 Flash for that. But now, we use Qwen 3.5 4B locally. Gemini gives a better result, but local Qwen is good enough.
Once extracted, we save these facts into SQLite. We also make sure to add references back to the original conversation.
Fact Sheet Injection
Extracted facts are great. But we can't feed all these into an LLM context. We wanted to find a way to pick what's really relevant at a given moment. We tried different ideas like ranking facts with deduping & heuristics. But finally we found the ideal solution. Here's how it works:
How Injection Works
- Based on these facts, we generate a factsheet of ~120 facts
- It includes facts from all the categories. There are min & max for each
- Then we feed this fact sheet, every time a user starts a conversation
- So, the model knows about you. It's like a short term memory with bio data.
Fact Sheet Generation
- We generate this again using a worker. It runs every 30 minutes
- We use the same LLM we use for fact extraction. But you can literally use any model.
- We describe what a fact & fact sheet are
- We feed it the previous fact sheet
- We feed it the currently generated facts & facts generated over the last couple of hours
- Then we ask it to generate a new fact sheet based on the above
This seems like a very simple approach, but works really well. Here's an example fact sheet.
RAG is Not Your Enemy
Some people don't like to use RAG. We understand why. We think we found a much safer way to use RAG. Here's how it works at OKBrain Harness.
- First, this is optional
- We use a local model to get the vector embeddings (nomic-embed-text or qwen3-embedding in our case) (We recommend using an open-weight model always for embedding)
- We vectorize only the extracted facts. So, it's relevant & light on processing too.
- We fetch 100 similar facts with every user question
- Then we rank these facts with similarity, time created, categories & etc
- After that we pick top 10 & prepend it with every user question
- It runs locally & it's token efficient. There's no significant delay in the overall latency as well.
Explicit Fact Search & Conversation Search Tools
Sometimes, the provided facts are not enough. For those cases, we gave some tools to query the SQLite for facts & conversations. This works wonders & now the models can learn all about you. Here are the tools we provide:
- Search Facts - This will do SQL LIKE search for stored facts
- Search Conversations - Here it searches facts & finds the linked conversations. So, it's fast & avoids the noise in the conversations as well.
- Search a Conversation - Here it can search a given conversation for user & agent messages
Covering the Blind Spot
We generate fact sheets every 30 minutes. So, there's a window where models don't know what happened. In order to fix that gap, we do something simple.
Rather than extracting facts, we attach questions asked by the user in that time window. So, the model knows what was discussed even in a different conversation.
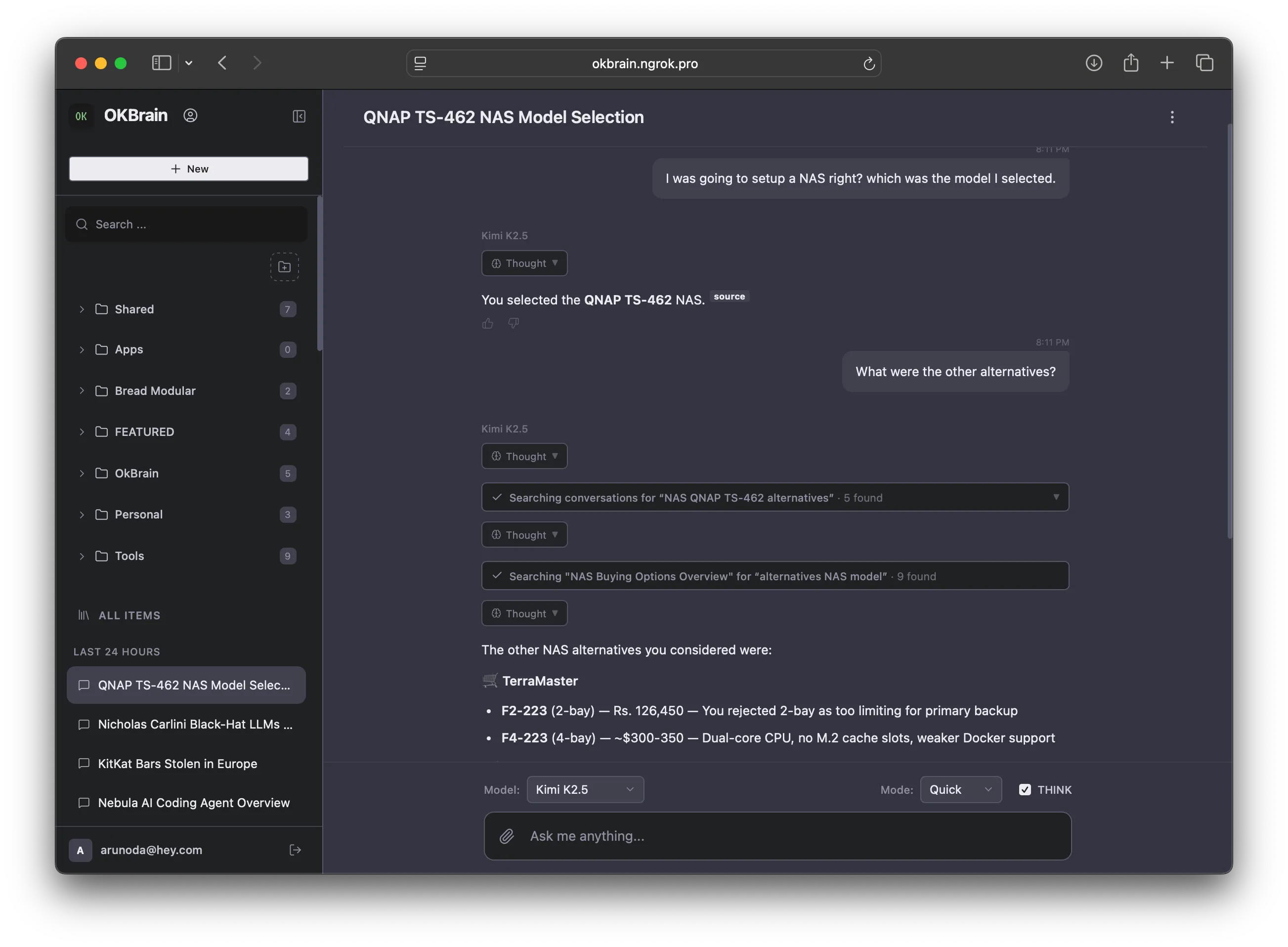
We used this memory system with OKBrain Harness for two months & now it literally knows a lot of things about the users. Sometimes, we even wonder how it learned these things. Luckily, we can do a simple search & find out the related conversation.
BTW: OKBrain Harness is not a cloud service. By users, we mean our local deployments. Not external users.
This is far from an ideal solution. But it's good enough for us & works well with any model. We think that having a semi-structured memory system like this helps over letting the agents take care of it. If we have unlimited tokens, huge context windows & smart models like Opus, yeah agents will figure it out. But not everybody has that sort of luxury. At least, Anthropic is reminding people about it :P